지난 포스팅의 경기 결과를 예측하려는 시도는 완벽한 실패로 끝났다. 그리고 연구 주제 자체도 신박한 아이디어는 아니다. 그래서 이 주제로 연구실 세미나로 발표한 이후 여러 문제점을 깨달았고 논문은 나의 블로그 일기장이 아니기 때문에 연구의 고삐를 말 그대로 180도 수정했다. 그래서 나온 결과가 “A Confidence-Calibrated MOBA Game Winner Predictor”라는 논문이며 해당 논문은 IEEE Conference on Games 2020에 프로시딩 되었다.
Confidence-Calibrated model
논문 제목에도 들어가 있는 Confidence-Calibrated model은 한 마디로 표현하면 딥러닝의 아웃풋으로 나오는 확률이 얼마나 reliable하냐를 뜻하냐는 것이다. 개와 고양이를 분류하는 classifier가 80%확률로 고양이라고 하는 사진들을 모아서 accuracy를 측정했을 때 90%확률로 진짜 고양이라면 이는 undercondence한 model이다. 반대로 accuracy가 60%라면 overconfidence한 모델이고 이것이 현대의 대부분의 neural network가 가지고 있는 문제점이다. accuracy를 80%로 맞춘다면 해당 모델은 confidence-calibrated하다고 할 수 있다.
딥러닝에서 Confidence-Calibrated model을 구현하기 위한 초기 시도는 icml 2017에 소개된 “On calibration of modern neural network”란 논문에서 다루었다. 해당 논문에서는 temperature scaling이 전반적으로 가장 좋은 성능을 보여준다고 하여 우리 논문에서도 사용하였다.
그렇다면 LoL 데이터셋에서도 temperature scaling이 잘 작동될까? temperature scaling은 신경망의 입력과 상관 없이 logit값이 같다면 똑같이 scaling이 진행된다. 예를 들어 게임 시작 후 5분 경의 데이터와 30분 경의 데이터가 똑같이 레드 팀에 80% 확률로 이긴다고 해도 temperature scaling을 거치면 똑같이 승리 확률이 76%로 바뀌는 것이다. 이는 우리의 직관과는 다르다.
Input Uncertainty 측정을 통한 Calibration
그러나 위의 Temperature Scaling과 같은 방법들은 이미지와 텍스트 도메인에서 실험한 결과이다. 이는 직관적으로 생각해봤을 때 승리팀을 정답 레이블로 한 LoL 데이터셋에 비해 훨씬 명확한 답을 가지고 있다.
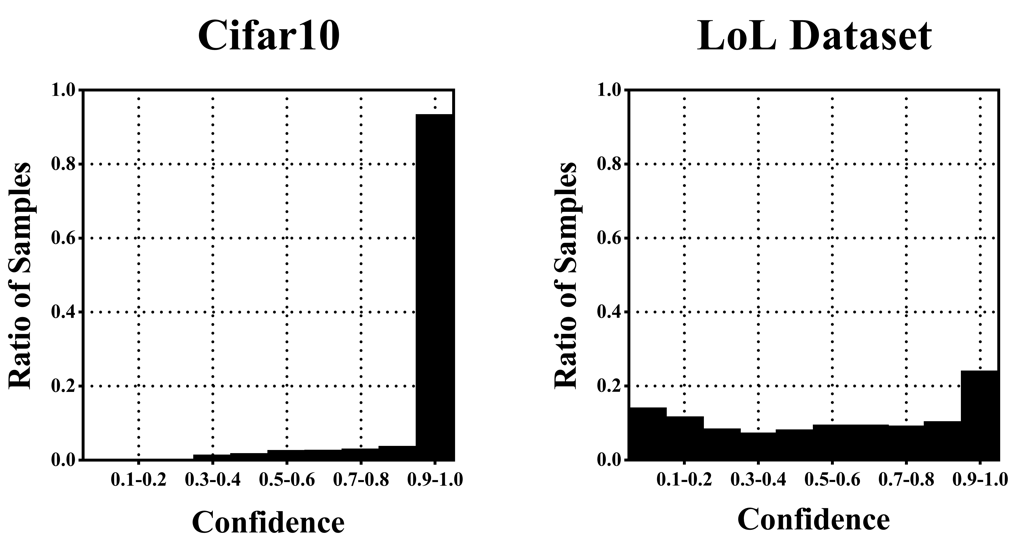
위 그림은 이미지 데이터셋과 LoL 데이터셋의 Confidence 분포의 차이를 명확하게 보여준다. 이미지는 대부분의 test sample 들의 Confidence가 90% 이상이다. 반면 LoL 데이터셋은 Confidence가 고르게 분포되어 있다. 따라서 이를 고려하는 Calibration이 진행되어야 한다.
그래서 생각한 것이 Input Uncertainty를 통하여 Calibration을 진행하자는 것이다. 레드 팀과 블루 팀 중 어느 쪽이 이길 확률이 높냐는 classification에서 Data Uncertainty를 측정하기 위해 “What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?” 에서의 Data Uncertainty Estimation의 방법을 활용했다.
실험 결과
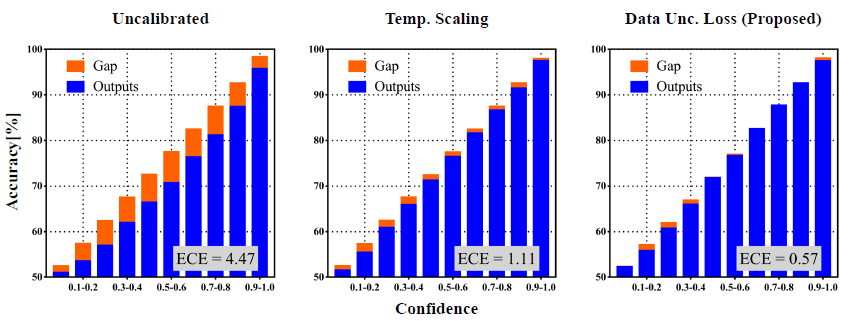
Calibration의 성능을 평가하는 Metric으로는 Expected Calibration Error(ECE), Maximum Calibration Error(MCE) 등이 있지만 가장 직관적으로 성능을 확인할 수 있는 그래프는 위의 Reliability Diagram 이다. 파란색 막대가 해당 범위에서의 Accuracy를 의미하고 주황색 막대가 Accuracy와 Confidence 평균의 차이를 의미한다. 당연히 주황색이 많이 보일수록 안 좋은 결과를 보이는 것이다. 이 그림을 통해 우리는 제안한 방법의 성능이 가장 좋다는 것을 확인할 수 있다.
그림의 DU Loss 가 뭔지 다른 Metric은 어떤 결과를 보이는지는 논문에 좀더 자세한 설명이 있다.
첫 논문을 쓰고서…
우여곡절이 많았다. 첫 논문을 역경 없이 스무스하게 나온 사람이 얼마나 있겠냐마는. 첫 블로그 글에서 보듯 파이토치 연습 할 겸 사이드 프로젝트로 시작한 것이 여기까지 오게 되었다.
가장 많이 드는 생각은 논문의 컨텐츠가 되는 실험 결과가 나왔을 때는 논문을 쓰는 전체 프로세스를 봤을 때 30% 밖에 진행하지 않은 것이다. 논문의 그래프와 표를 그려야 하고 영어로 논문을 써야하며 몇 차례 혹은 수십차례가 넘어갈 수 있는 수정을 거치고 컨퍼런스 혹은 저널에 투고도 해야한다. 그리고 저널이라면 리비전을 컨퍼런스라면 발표 준비도 필요하다.
그래도 연구하는게 재밌어서 다음 연구를 하고 있다.