뿌요뿌요의 추억
어렸을 때 공부하라고 보낸 학원에서 게임했다. 물론 게임만 했던건 아니고 당연히 쉬는시간 중간중간 마다 했으며 내가 했었던 게임 중에는 컴파일의 뿌요뿌요2가 있었고 바둑이나 쿠키런을 강화학습으로 정복했듯 뿌요뿌요를 강화학습으로 훈련시킨다면 재미있는 프로젝트가 될 거라 생각했다. 필자는 처음 강화학습을 접했을 때 이 글을 보고 조금이나마 쉽게 텐서플로우와 강화학습 코드를 이해할 수 있도록 노력했다.(정말 문자 그대로 아~무것도 모른다면 블로그의 이전 글 중 강화학습 부분을 읽어 기본 지식은 습득한 상태라고 가정한다)
또한 즉시 실행으로 구글에서 그렇게 자랑하는 tensorflow 2.0으로 개발을 진행해보고 싶었고(tensorflow1의 sess.run이 싫기도 했고) 그에 따라 tf2 beta버전을 주로 사용하였다.
학습시킨 결과는 다음과 같다.
하드웨어 환경은 ryzen 1700X와 Nvidia의 Titan V를 사용했고, cuda 10.0을 Ubuntu 16.04LTS와 python 3.5를 virtualenv 함께 사용했으나 강화학습은 NN의 깊이가 깊지 않기 때문에 CPU로 학습하는 것과 GPU로 학습하는 것의 차이가 없다고 봐도 무방하다. 필자가 직접 로컬 환경에서 구동하진 않았으나 무겁지 않은 코드니 충분히 개인이나 Colab에서도 구동시킬 만하다고 생각한다.
언제나 가장 힘든 것 - 개발 환경 구축
openAI gym으로 뿌요뿌요 환경 만들기
강화학습을 안다면 개발 환경을 구성하는 것이 매우 중요하다는 것을 알 것이다. 에이전트가 어떤 액션을 한다면 다음으로 어떤 reward가 나오고 그 다음 환경은 어떤지 잘 뽑아내주는 환경을 말하는 것이다.
강화학습에서 최초로 Neural Network를 사용한 DQN 논문인 Playing Atari with Deep Reinforcement Learning에서는 1970년대 Atari 게임을 통해 강화학습의 유용성을 입증했다. 우리가 직접 하나하나 손수 파이썬으로 Atari 환경을 구성하는 것도 좋은 방법이나 오픈소스인 openAI사의 gym 환경을 세팅하여 개발하는 것이 우리 같은 학습자의 입장에서는 훨씬 좋은 방법이라고 생각한다.
어찌저찌 컴퓨터에 gym 환경을 구축했다면 이번엔 뿌요뿌요 환경을 gym으로 만들 차례다. gym이라는 것은 강화학습 환경을 구축하는 툴킷(이라고 공홈에 적혀있다)이고 그 gym 환경 안에 뿌요뿌요 환경을 추가해야 하는데 이 또한 내가 하나하나 손수 코딩하는 수고를 덜어준 고마운 분이 있었다. 다음 링크가 해당 깃헙이며 README도 여타 레포보다 비교적 쉽고 자세하게 적혀있기 때문에 설치하는 데 많은 애를 먹진 않을 것이다.
gym의 사용 방법을 이해 하는 데는 공식 홈페이지가 물론 가장 정확하나 카카오 AI 브런치에서 슈퍼마리오 강화학습을 쭉 읽어보는 것이 반드시 도움이 될 것이고 핵심만 간추린 설명이 간단하고 쉬운 블로그 글도 찾을 수 있었다.
후에 코드 분석에서 조금 더 자세히 다룰 예정이지만 필자가 해보거나 본 뿌요뿌요는 뿌요뿌요2와 뿌요뿌요 vs 테트리스가 있는데 해당 언급한 게임과 규칙이 완전히 동일하게 적용되지 않는다. 예를 들면 가장 위 왼쪽 세 번째 뿌요가 막혔을 때 done이 나오는 것이 아니며 어느 순간에는 -1의 reward를 리턴하기도 한다.
뿌요뿌요 환경 뜯어보기
기본적으로 해당 깃허브에서 README를 따라 설치 했다면 사용 방법은 gym과 마찬가지로 간단하다. register를 한 이후 make를 통해 환경을 만들고 해당 환경에서 action을 선택하여 step을 취해주면 해당 액션을 취했을 때의 reward와 done 여부 다음 state가 나온다.
make 할 수 있는 환경의 종류로는 여러가지가 있는데 크기와 관련하여 small, wide, tsu, large로 나눌 수 있고 혼자서 점수를 높이는 것이 목적인 모드와 두 사람(혹은 프로그램)이 연쇄를 많이 하는 그러니까 내가 어릴 때 많이 하던 vs모드가 있다. vs모드에는 방해뿌요까지 구현되어 있으니 vs 모드에서 강화학습으로 상대방을 이기는 AI를 만드는 것도 재미있어 보인다. 인게임상에서 흔히 볼 수 있는 환경은 tsu 이고 혼자서 하는 것은 연습모드, 둘이서 하는 건 뭐 둘이서 하는 거다. 필자는 혼자서 뿌요뿌요 점수를 올리는 agent를 만드는 것을 목적으로 했다. 앞으로는 뿌요뿌요 환경이라 함은 tsu 크기에 혼자서 플레이하는 환경을 일컫도록 하겠다.
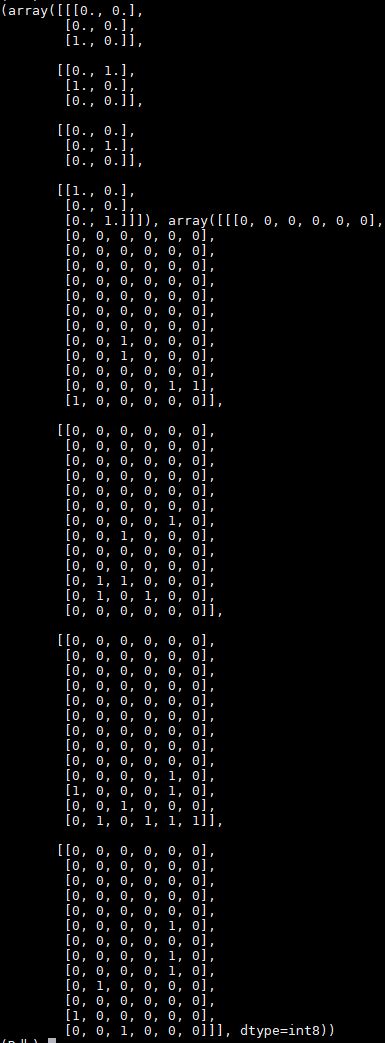
먼저 state는 list 자료형이지만 numpy array 자료형으로 구성된다. 3x2 array 가 4개 13x6 array가 4개 합쳐진 리스트 자료형이다. tsu 환경에서 색이 4개가 있으므로 각 array가 4개씩 있게 되며 각각의 3x2와 13x6의 2차원 배열은 각 색깔의 뿌요가 어디 있는지 나타낸다. 위 그림을 보고 설명을 본다면 이해하기 쉬울 것이다.
reward는 다음 뿌요뿌요 위키를 통해 산정한다고 한다. 상기했듯 episode가 done에 가까워졌을 때 reward가 -1이 나오는 것은 모듈 코어상의 버그로 추정되지만 코어 안에서 필자가 수정하진 않았고 코드 상에서 버그를 수정하는 부분을 넣었다.
done은 말 그대로 done. step 이후 episode가 끝날 때 1, 아닌다면 0이 반환된다.
결과
결과적으로 학습에 성공했다고 말할 수 있는 알고리즘은 vanila Actor Critic과 A3C에서 Asynchronous를 뺀 A2C이다.
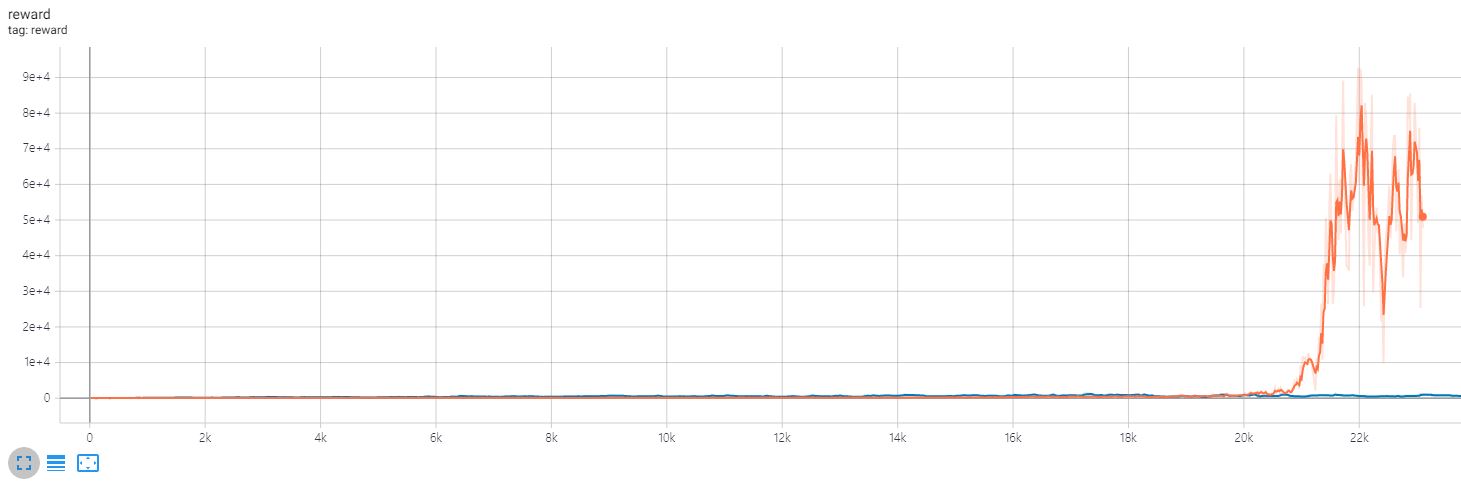
해당 그래프는 상기한 사양의 컴퓨터로 44시간 가까이 학습한 결과이며 빨간색이 A2C이고 파란색이 AC인데 A2C의 reward가 exponential하게 늘어나는 반면 AC는 제자리걸음을 보인다.
필자의 깃허브 레포에서 볼 수 있듯 PPO도 구현하려 했으나 확실히 구현에서 잘못된 점이 있어 학습이 이루어지지 않았다. 해당 코드를 수정하여 PPO로도 학습되는 것을 볼 수 있다면 필자도 기쁠 거 같다.