다음 글은 tensorflow 2.0으로 ActorCritic 알고리즘을 구현하여 뿌요뿌요의 점수를 높게 만드는 프로젝트를 진행한 결과이다. 과거의 나와 같이 강화학습 코드에 처음 입문한 사람이 조금 더 구현에 쉽게 접근할 수 있도록 주석과 설명을 첨부하려 한다. 해당 글을 읽기 전 이웅원님의 A3C 설명 영상을 본다면 다음 코드를 이해하는데 훨씬 도움이 될 것이다.
Model.py
Model 클래스는 케라스의 모델을 상속하여 DNN를 구성하는 역할을 한다.
init함수에서 그러니까 model 클래스가 호출됨과 동시에 Neural Network가 생성된다. ActorCritic에서 Neural Net은 2개가 필요한데 하나는 action을 지정하는 Actor와 해당 state에서의 value가 얼마인지 추정하는 (수식으로 말하자면 v(s))Critic 부분이다. 결과적으로 action_value함수를 통과하면 action이 logit에서 ProbabilityDistribution을 통해 샘플링되어 나오고 그와 동시에 추정된 value 값도 나오게 된다. 두 NN은 모두 full-connected layer 2개로 구성된 MLP이며 각각의 fc는 128의 perceptron으로 제작되었다.
AgentInit.py
AC의 Agent를 정의하기 위한 첫 번째 단계다. 받아온 model을 self를 통해 클래스 내 지역변수로 만들고 model을 컴파일하여 loss가 감소하는 방향으로 모델이 튜닝되는 것을 시작한다. 하이라이트는 이 다음 트레이닝 부분이다.
train.py
실질적으로 NN의 파라미터들이 학습되는 부분이다. NN내부의 파라미터가 backpropagation이 수행되어 값이 변화할 때 1update가 진행되는데 현재 코드에선 update의 횟수를 기준으로 삼이 언제 training을 끝낼지 결정한다. train 함수 내의 유일한 for 문 부분을 수정한다면 ep_count를 사용해 episode 단위로 결정할 수 있고 time 라이브러리를 잘 이용한다면 몇 시간이 지난 후 학습을 멈출지 설정할 수 있다.
이 함수에서 한 가지 언급하고 싶은 부분이 있는데 reward를 그대로 사용하지 않고 로그를 취하여 사용했다는 부분이다. 뿌요뿌요를 플레이 한 사람이라면 알겠지만 뿌요뿌요의 스코어는 연쇄 숫자가 커질 때 마다 기하급수적으로 늘어난다. 연쇄가 발생한다면 매우 좋겠지만 초반 불안정한 학습으로 시간이 지난 후에도 학습이 만족스럽게 되지 않는 문제가 발생했다. 따라서 로그를 통해 불안정한 reward를 보완했다.
utils.py
이 부분은 obs_rank_down과 _returns_advantages함수로 구성되어 있다. obs_rank_down은 3차원이었던 observation을 그저 쭉 펴서 1차원으로 만든다. 다른 역할을 없다. 그냥 쭉 편다.
_returns_advantages는 return과 advantage를 반환하는데 return은 r+(gamma)v(s+1)이고 advantage는 r+(gamma)v(s+1)-v(s)이다.
loss.py
모델에 사용될 loss를 정의한다. value_loss는 return과 해당 state의 예상 value, 그러니까 v(s)와 비슷해지도록 학습이 진행된다.
logit_loss는 ,위의 A3C설명 영상을 보면 알겠지만, advantage를 logit과 action의 cross-entorpy에 곱함으로써 logit을 action 방향으로 Advantage에 따라 유도되게 또는 유도되지 않게 만든다. 정확히는 advantage가 양수라면 logit이 행한 action과 비슷해지도록 음수라면 비슷해지지 않도록 만드는 것이다. 그렇게 해주기 위해 tensorflow의 CE함수에서 sample_weight라는 인자를 통해 advantage를 넘겨 주는 것이다.
main.py
이 모든 것을 아우르는 메인함수다. gym_puyopuyo를 register를 통해 뿌요뿌요 환경을 추가하고 model과 agent를 정의한 후 agent내의 train 함수를 트레이닝 하면 끝이다!
Result
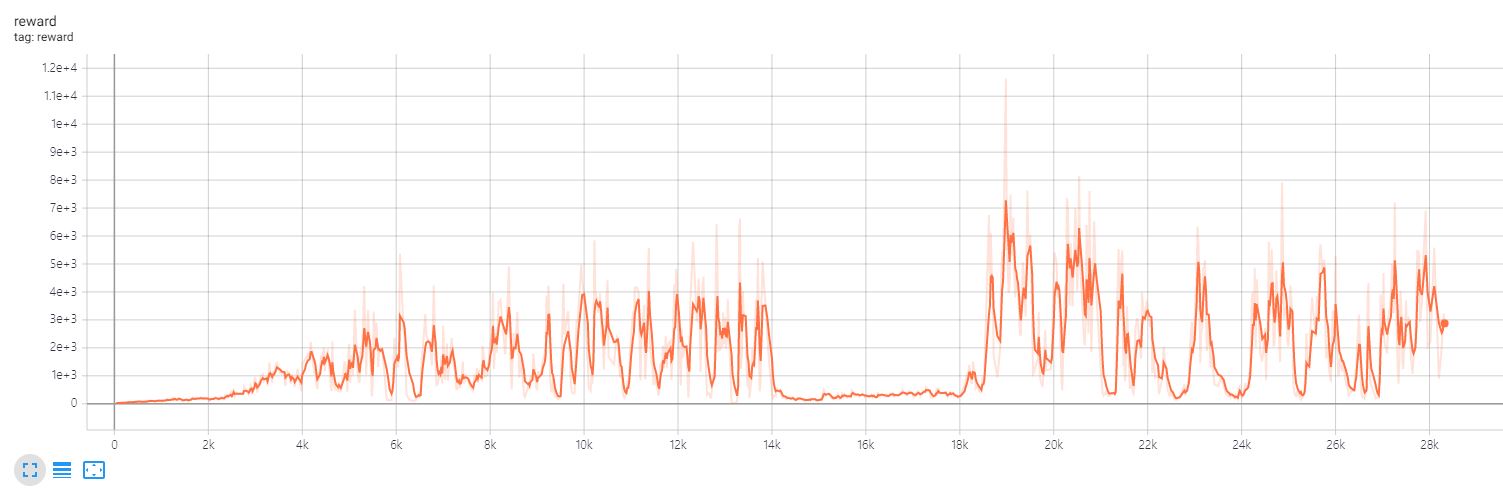 소스 코드를 잘 보면 알겠지만 그래프는 20에피소드마다 reward의 평균을 내어 그래프화 한 것이다. 14000~18000스텝 부분에서 local minimum에 stuck된 것을 추정된다. 그래도 reward의 최대값이 12000을 찍는 등 어느정도 학습이 된 결과를 보인다.
소스 코드를 잘 보면 알겠지만 그래프는 20에피소드마다 reward의 평균을 내어 그래프화 한 것이다. 14000~18000스텝 부분에서 local minimum에 stuck된 것을 추정된다. 그래도 reward의 최대값이 12000을 찍는 등 어느정도 학습이 된 결과를 보인다.