다음 글은 tensorflow 2.0으로 A2C 알고리즘을 구현하여 뿌요뿌요의 점수를 높게 만드는 프로젝트를 진행한 결과이다. 과거의 나와 같이 강화학습 코드에 처음 입문한 사람이 조금 더 구현에 쉽게 접근할 수 있도록 주석과 설명을 첨부하려 한다. 해당 글을 읽기 전 이웅원님의 A3C 설명 영상을 본다면 다음 코드를 이해하는데 훨씬 도움이 될 것이다. 코드의 전체적인 뼈대는 이전 글의 AC와 동일하며 이 글은 AC와 비교해 달라진 점과 내가 구현하지 못해 조금 아쉬웠던 점을 위주로 작성할 것이다.
train.py
ActorCritic과 A2C에는 전 코드에 걸쳐 소소한 차이가 있지만 알고리즘적인 차이가 가장 많이 나타나는 train 함수 내부만을 살펴볼 것이다. 가장 큰 차이점은 수집한 데이터를 batch 만큼 저장한다는 점이며 수집한 batch를 통해 향상된 Advantage를 구하여 학습을 진행한다는 것이다. batch 만큼 reward, action, observations(state)가 저장되고 저장된 data 들을 _returns_advantages 함수를 통해 함수 이름처럼 Advantage를 return 한다. 나머지는 거의 같다. loss를 정의한 것도 NN의 model을 128개짜리 MLP로 구성한 것도.
Result
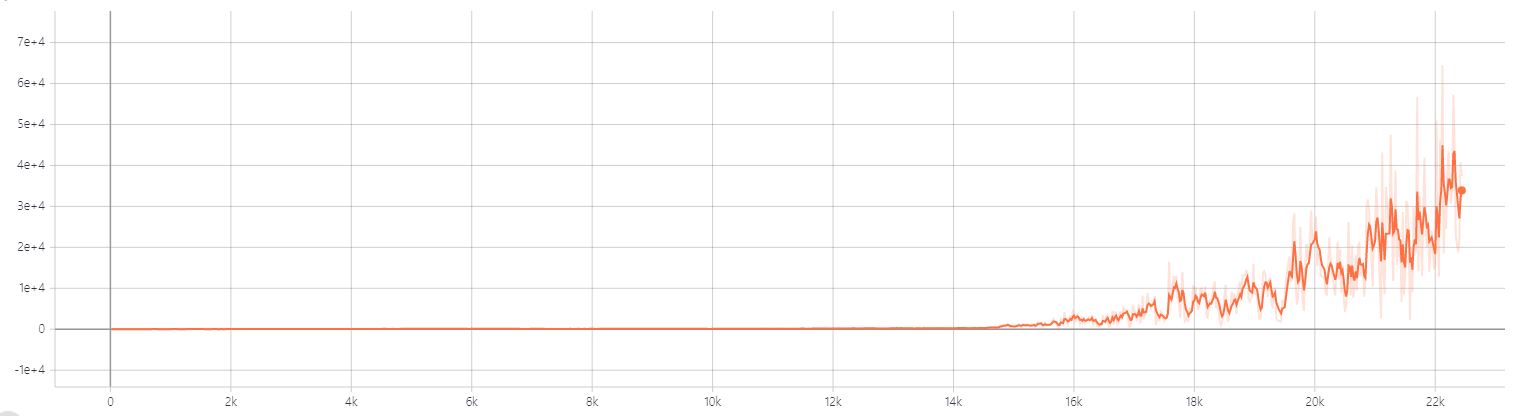 소스 코드를 잘 보면 알겠지만 그래프는 20에피소드마다 reward의 평균을 내어 그래프화 한 것이다. 14000~18000스텝 부분에서 local minimum에 stuck된 것을 추정되는 ActorCritic과 달리 A2C는 14000즈음의 스텝에서 본격적으로 exponential 하게 학습되기 시작한다. 사실 14000스텝까지만 학습하여 확대해 봐도 지수함수적으로 reward가 증가하길래 언제까지 같은 비율로 증가하나 궁금에서 꽤 오래 돌려본 것인데, 적어도 그림에서 보이듯 22000episode 까지는 어느 수치로 수렴하진 않았다.
소스 코드를 잘 보면 알겠지만 그래프는 20에피소드마다 reward의 평균을 내어 그래프화 한 것이다. 14000~18000스텝 부분에서 local minimum에 stuck된 것을 추정되는 ActorCritic과 달리 A2C는 14000즈음의 스텝에서 본격적으로 exponential 하게 학습되기 시작한다. 사실 14000스텝까지만 학습하여 확대해 봐도 지수함수적으로 reward가 증가하길래 언제까지 같은 비율로 증가하나 궁금에서 꽤 오래 돌려본 것인데, 적어도 그림에서 보이듯 22000episode 까지는 어느 수치로 수렴하진 않았다.
레포에 PPO도 있는데?
이 깃허브 레포지토리에는 PPO 라는 이름의 파일과 new_PPO라고 되어있는 파일이 모두 있다. 그러나 결과적으로 말하자면 PPO를 구현하는데에는 실패했다.
PPO는 AC와 A2C와는 다른 방법으로 파라미터를 조정한다. Advantage를 취하는 방법도 GAE라는 새로운 방법을 사용하지만 그보다는 cliping을 통해서 파라미터의 변환 방향을 결정한다. 필자는 TF 2.0과 keras의 AutoGradient함수 중 하나인 train_on_batch를 사용하여 어떻게든 구현해보려고 했으나 결과적으로 학습이 되지 않았다. pdb를 통하여 디버깅을 진행하였는데 pdb로 디버깅을 한다면 loss 함수 내의 변수들을 볼 수 없다는 점이 치명적으로 작용했다. pdb로 디버깅시 model을 compile 할 때 한 번만 loss 함수 내로 접근하는것을 학습이 진행되는 중에도 볼수 있게 tf.debugging api를 사용해보기도 하는 등 오만가지 방법을 동원해 보았으나 실패라고밖에는 할 수 없는 결과만 있었다.
이 프로젝트를 무기한 연기하며 적는 아쉬운 점들.
가장 아쉬운 점은 상기했듯 PPO를 제대로 구현하지 못해 PPO에서 뿌요뿌요를 돌려보지 못한 것이다. 그리고는 아쉬운 점이라기보단 개선할 수 있는 방향인데, 우선 Model을 MLP를 사용하는 것이 아니라 CNN을 사용한다면 어느정도의 성능 향상이 보장되어 있으리라 생각한다. gym_puyopuyo 환경에서 제공하는 state는 정사각형의 input이 아니니 좌우로 살짝 padding을 준 3차원 혹은 4차원(색깔의 수에 따라 다른)의 input으로 CNN을 구성하여 Policy와 Value Network를 구성했을 때의 결과가 궁금하다.
또한 하나의 환경의 뿌요뿌요에서 reward를 많이 받는 방향으로 학습하는 것이 아니라 Agent를 2개 만들어 versus 환경에서 이길 때 1 졌을 때 -1의 reward를 준다면 과연 상대에게 이기는 방향으로 학습이 진행될까도 주요 의문점이다. 물론 versus환경도 실제 뿌요뿌요와는 다르다. gym 환경에선 step 하나가 지나가면 좌측과 우측 게임 모두 하나의 뿌요가 땅에 떨어지는 그런 환경이다. 즉 real world에선 한쪽을 빨리 쌓을수도 다른쪽은 느리게 쌓을수도 있을 수 있는 환경이라면 학습환경은 두 명(?)의 Agent가 쌓는 속도가 완전히 동일하다는 의미이다.
한두 달 정도 이 프로젝트를 진행했는데 처음으로 텐서플로우를 통해서 내가 ‘창조’해낸 프로그램이다. 이런저런 삽질도 많이 했고 학습이 되지 않았던 적도 수없이 많다. 프로젝트를 진행하는 중 DeepMind의 AlphaStar를 개발하고 있는 연구원을 세미나에서 만날 수 있었다. 본인도 알파스타를 제작할 때 이게 진짜 이길 수 있을까, 학습이 될까하는 수많은 의구심과 시간을 보냈다고 했는데 이 말이 이 프로젝트를 진행하며 내게 가장 힘이 되었던 말이었던거 같다.